

为什么我的 Solana 应用这么慢?网络距离为何如此重要
为什么我的 Solana 应用这么慢?网络距离为何如此重要

我们经常听到交易者和构建者这样说:
- "我在运行类似的策略,但只有我的机器人成交延迟。"
- "价格更新正常,但我的交易来不及提交。"
- "我换过 RPC 提供商了,但性能并没有真正改变。"
面对这些情况,第一反应通常是:
- "我的代码一定是太慢了。"
- "我的服务器配置可能不够好。"
这两者确实都很重要。
但在 Solana 这样的高速环境中,有一个更根本的瓶颈往往最先出现:网络距离。
在 Solana 上,有无数 dApp、DeFi 协议和市场在链上运行,其中许多依赖机器人进行自动化交易。在这种实质上的高频交易(HFT)环境中,能否比竞争对手更快地检测事件、更快地执行操作,将决定你的优势和盈利机会。
在本文中,我们将探讨为什么在 Solana 上追求快速检测和低延迟执行时,网络距离会成为决定性因素,以及 ERPC 的 Bundle 方案和 VPS 产品是如何设计来解决这些需求的。
为什么感觉"只有我的应用很慢"?
首先,让我们整理一些常见的情况:
- 你的服务器有充足的 CPU 和内存,但交易反应仍然比竞争对手慢。
- 你通过 getProgramAccounts 或日志订阅看到了新事件,但你的交易提交总是慢半拍。
- 你尝试了多个云环境和多个 RPC 提供商,但没有感到突破性的改善。
面对这些情况,许多开发者试图从代码或算法中挤出更多性能。
这是有效且重要的努力,但有一个更深层的结构性问题可能依然未解:
- 你可能一开始就在一个"遥远的网络"中作战。
- 从领导者验证者的角度来看,你的应用可能位于物理上不利的位置。
如果这些条件成立,无论你怎么优化软件,都永远无法完全达到你期望的性能水平。
要真正利用 Solana 的速度优势,你需要同时考虑三个层面:
- 代码
- 硬件
- 网络
其中,你通常应该首先调优的是"网络距离"。
决定速度的三个层面
代码(软件和策略)
对于 Solana 上的机器人和 HFT 类系统,你的代码和策略直接影响结果:
- 使用哪些事件作为触发器
- 在什么条件下建仓和平仓
- 去除了多少不必要的 I/O,以及并行处理的效果如何
这些是许多开发者最直观的优化手段。代码层面的改进至关重要,但它只是拼图的一块。
硬件
下一个重要因素是服务器性能。仅仅"容量足够"是不够的。你需要关注:
- 高主频 CPU(单核处理任务的速度有多快)
- 核心数量(能同时运行多少任务)
- 内存容量和通道数(大型工作集能否无阻塞地访问)
- NVMe 等快速存储(确保日志和数据写入不会成为瓶颈)
交易工作负载通常需要处理大型索引和状态。在这种场景下:
- 大容量 CPU 缓存
- 充足的 RAM,无交换风险
可以带来更稳定的性能。
当然,更高性能的环境成本也更高。最终,你需要找到一个平衡点,使策略的预期收益能够支撑硬件投入。
网络
最容易被忽视、但往往对延迟影响最大的因素是网络。
通过 CPU 优化,你可能节省几百纳秒到几微秒。
通过网络优化,你可能实现的差异突然就在几百毫秒的范围内。从量级上看,网络变化的影响可能是 CPU 优化的千倍。
即使你拥有:
- 强大的服务器
- 高效的软件
- 精心设计的策略
将资源放在错误的网络位置会使大部分努力化为乌有。第一步应该是为你的应用选择正确的数据中心和正确的网络。
重建对网络距离的直觉认知
因为网络不像 CPU 或 RAM 那样可见,所以很难建立对它的直觉。为了使其更容易理解,可以用交通运输来类比。
当你思考互联网时,想象:
- 你的服务器是出发点
- Solana 验证者或 RPC 端点是目的地
然后想象在这两点之间驾车或乘飞机。
短途旅程:
- 红绿灯和十字路口更少
- 更少受到拥堵影响
- 到达时间变化不大,通常准时
长途旅程:
- 需要高速公路、隧道和枢纽机场
- 经过许多中间点
- 更容易受到施工、事故或交通拥堵的影响
因此,到达时间的变化要大得多。
网络的行为方式相同:
- 更短的光纤电缆
- 更少的中间路由器和交换机(十字路口和枢纽)
意味着更短的往返时间和更少的抖动。
带宽(1Gbps、10Gbps、25Gbps)就像道路的车道数。
更多车道允许更多数据并行流动并减少拥堵。但即使有很多车道,如果路线过长或迂回,总行程时间仍然会很大。
在 Solana 上,如果你想要真正的速度,你需要两者兼备:
- 足够的车道(带宽)
- 短距离和高效的路由
Solana 的结构如何放大距离的影响
在 Solana 上,区块由每个 slot 轮换的领导者验证者产生,领导者分布在世界各地。
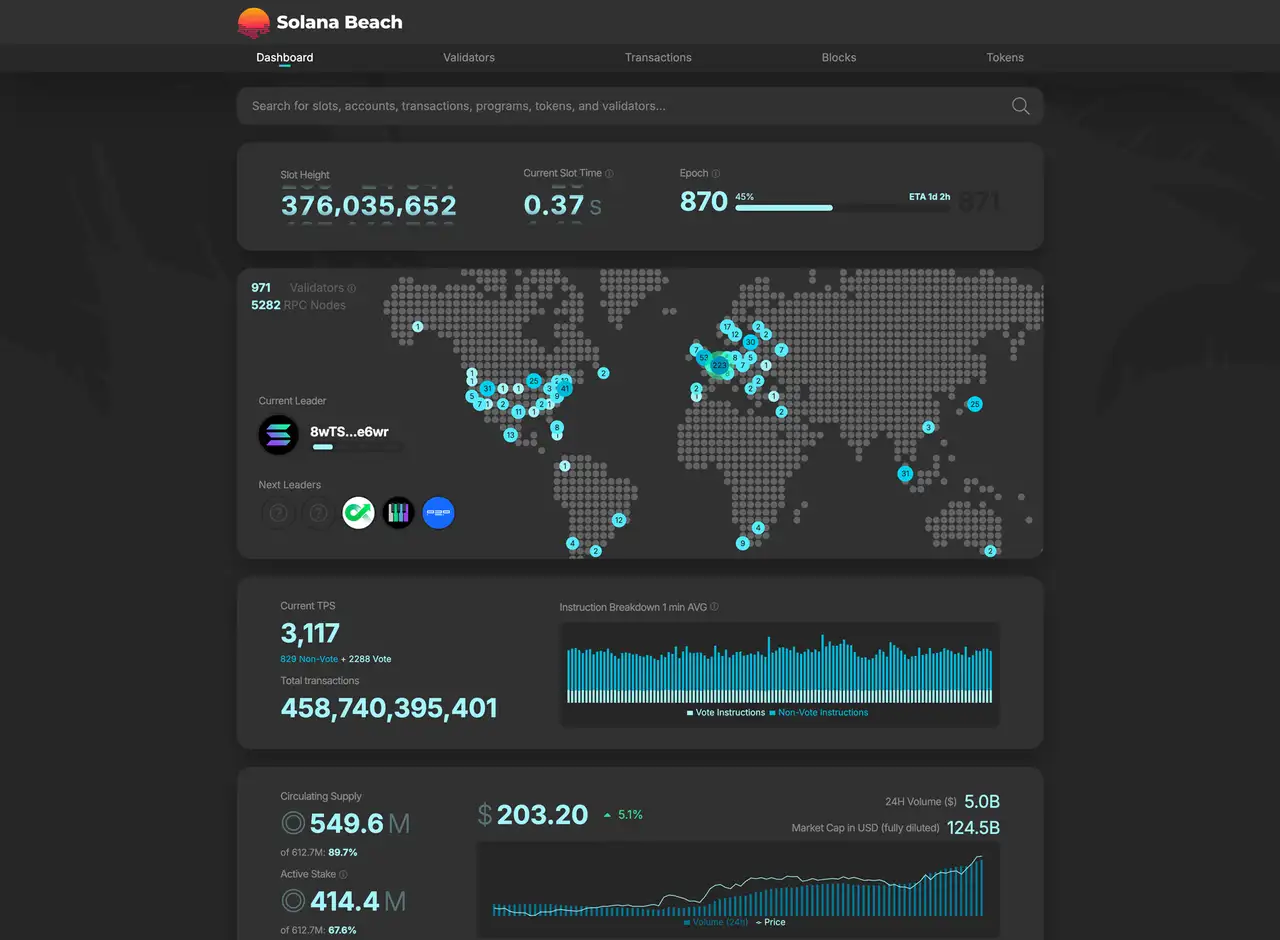
目前,许多验证者集中在法兰克福等地区。然而即便如此,领导者仍会在以下地区间轮转:
- 法兰克福
- 纽约
- 东京
- 新加坡
以及全球其他地区。
在这种结构中:
- 当领导者在法兰克福时,法兰克福网络内的节点具有明显优势。
- 当领导者在东京时,靠近东京的节点具有优势。
这是一个非常简单但非常强大的现实。
洲际通信仅往返 ping 就通常需要超过 100ms。例如:
- 从法兰克福追赶东京的领导者
- 从东京追赶纽约的领导者
这意味着当你加上 Shreds 流的接收和处理时,你的有效检测时机可能轻易延迟 1000ms 或更多。对于交易和监控应用来说,这个时间差距是巨大的。
为什么仅追求平均延迟是不够的
许多用户首先关注的指标是:
- 平均 ping
- 平均响应时间
这些是有用的,但在像 Solana 这样领导者逐 slot 在全球移动的网络中,以下两者之间存在巨大差异:
- 拥有良好的平均值
- 在关键时刻保持快速
即使某种配置显示平均延迟为 200ms,实际上你可能看到:
- 某些 slot 20ms
- 其他 slot 600ms
对于 0-slot 交易或任何依赖在 200-400ms 窗口内完成的策略,重要的不是平均值:
- 而是你能否以低延迟运行
- 在确切的关键时刻
- 在你的目标地区内
每当你试图命中位于另一个大洲的领导者时,总会有一些 slot 你在物理上无法跟上。
如果你只关注平均延迟而忽略这个现实,你将始终停留在"不知道为什么总在输"的状态。
定位你的应用实际在哪里变慢
接下来,让我们看看如何识别你的应用在哪里丢失了时间。
测量你当前的延迟
首先,用数字而不是感觉来测量到你当前端点的距离。
- 你当前的 RPC / gRPC / Shredstream 端点
- 位于与这些端点相同地区的节点
对它们运行 ping 测试并记录往返基准。
不要依赖单次测量。
在短时间间隔内运行多次 ping,查看中位数而不仅仅是均值。这能更好地反映当天的"路况"。
分离网络时间和应用处理时间
在你的应用中,记录:
- 请求发送时间戳
- 响应接收时间戳
- 内部处理的开始和结束时间
然后分离:
- 网络往返花了多少时间
- 实际业务逻辑花了多少时间
在许多情况下,你会发现:
- 你的代码在几毫秒到几十毫秒内就完成了
- 网络往返消耗了几百毫秒
典型瓶颈模式
一些常见模式包括:
- 从世界各地使用同一个 RPC 端点
- 从家里或办公室通过多层 VPN 和代理连接
- 将服务器部署在单一地区,试图从那里追赶全球的每个领导者
在这些配置中,Solana 的结构几乎保证你总是在从不利位置攻击某些领导者。
让网络距离为你所用的设计方法
要让网络距离为你服务而非与你作对,有几个关键步骤。
确定你实际在哪个网络中竞争
对于 Solana,你关心的"网络"是由验证者构建的网络。
领导者 slot 的频率与质押量成正比,因此:
- 托管大量质押验证者的网络
在实践中实际上成为"主要网络"。
首先了解:
- 哪些地区接近对你策略重要的市场或 dApp
- 你计划如何覆盖法兰克福等质押密集地区
这就是你决定实际要在哪些网络中竞争的方式。
数据中心和网络选择
对于 Solana 工作负载,了解以下几点至关重要:
- 你是否与关键验证者或 Jito Block Engine 在同一数据中心
- 还是通过 PNI(专用网络互联)与它们连接
互联网是全球性的,原则上你的应用放在哪里都能"工作"。
然而,对于 HFT 或近实时检测,主要问题变成了:
- 你能消除多少外部网络流量?
- 你能多接近零距离配置?
这些选择创造了第一个重大性能差距。
迈向多地区架构
理想情况下你会在每个地方都有部署,但你不需要从第一天就覆盖所有地区。
一个实际的第一步可以是:
- 法兰克福(主要网络)
- 加上一个对你策略重要的地区(纽约、东京、新加坡等)
从少量地区开始,你可以逐步扩展。
在每个地区,你:
- 在本地接收 Shreds 和 gRPC
- 在本地完成处理,或通过你自己的网络以最短路径转发
这使得维持"在任何给定时间在某处保持最快"的状态变得容易得多。
ERPC 的网络设计以及 Bundle / VPS 如何融入
现在,让我们将上述思路映射到 ERPC 的设计和产品线。
专为 Solana 打造的网络和基于 PNI 的架构
ERPC 是作为专为 Solana 设计的网络而构建的。我们精心选择:
- 质押集中的地区
- 托管主要验证者和 Jito Block Engine 的数据中心
- 通过 PNI 直接连接到这些核心位置的数据中心
构建出能够为 Solana 工作负载提供最大输出的拓扑结构。
互联网是全球性的,你的应用无论部署在哪里都能运行。
但当你关心 HFT 或快速检测时,必须首先选对数据中心和网络。ERPC 正是专门为 Solana 解决这个问题而设计的。
基于 Ping 的自动路由
对于共享 Solana RPC 端点,ERPC 不依赖 IP 地理定位。
相反,我们:
- 自动测量从每个地区到每个白名单 IP 的 ping
- 根据实际测量结果选择最近的地区
这避免了以下问题:
- 地图上看起来很近但实际走了远路的路由
- 基于过时地理定位数据库的路由决策
确保你始终通过我们能在实践中测量到的最短路径连接。
Solana RPC Bundle 方案

Solana RPC Bundle 方案为你提供:
- RPC(HTTP / WebSocket)
- Geyser gRPC(无过滤限制)
- Shredstream gRPC
整合在一个套餐中。
大多数团队通过 Geyser gRPC 开始他们的实时 Solana 之旅。由于它提供已解码的数据:
- 实现更简单
- 有许多示例和参考
- 学习曲线相对平缓
同时,专业团队会添加 Shredstream 以将检测和执行推向前沿。
通过 Bundle:
- 你可以保持现有的生产 RPC / gRPC 配置
- 可以以较小的额外成本添加 Shredstream
定价设计使你能够:
- 使用 RPC + gRPC 构建稳定的基础应用
- 然后在相同环境中开始试验 Shredstream,逐步进入更高性能
所有这些都不需要停止你的生产系统。
EPYC VPS / Premium Ryzen VPS
为了进一步缩短网络距离,ERPC 还在与 ERPC 端点相同的网络内提供 VPS 服务。
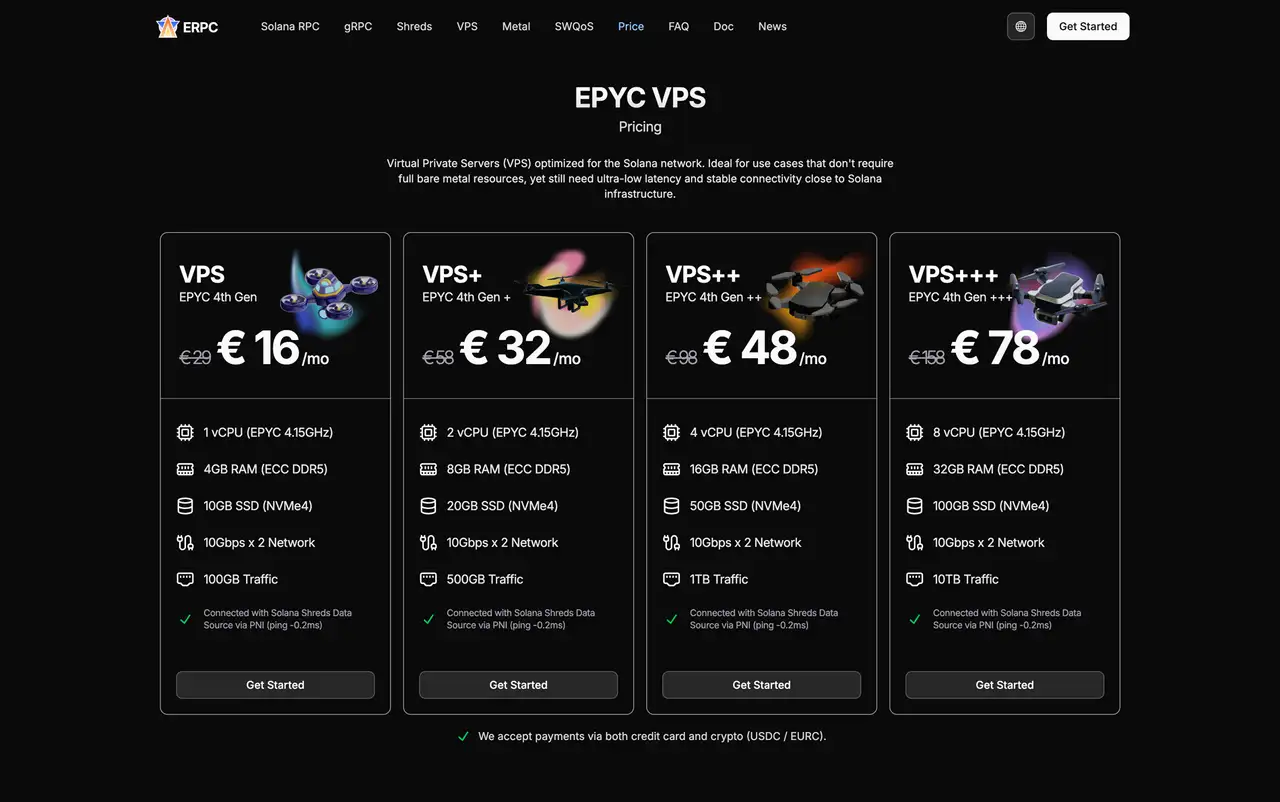
产品线包括:
- 性价比优异的 EPYC VPS
- 基于 5.7GHz Ryzen CPU 的 Premium Ryzen VPS
这些环境提供:
- 高主频 CPU
- ECC DDR5 内存
- NVMe4 存储
- 25Gbps × 2 网络
全部针对 Solana 工作负载进行调优。
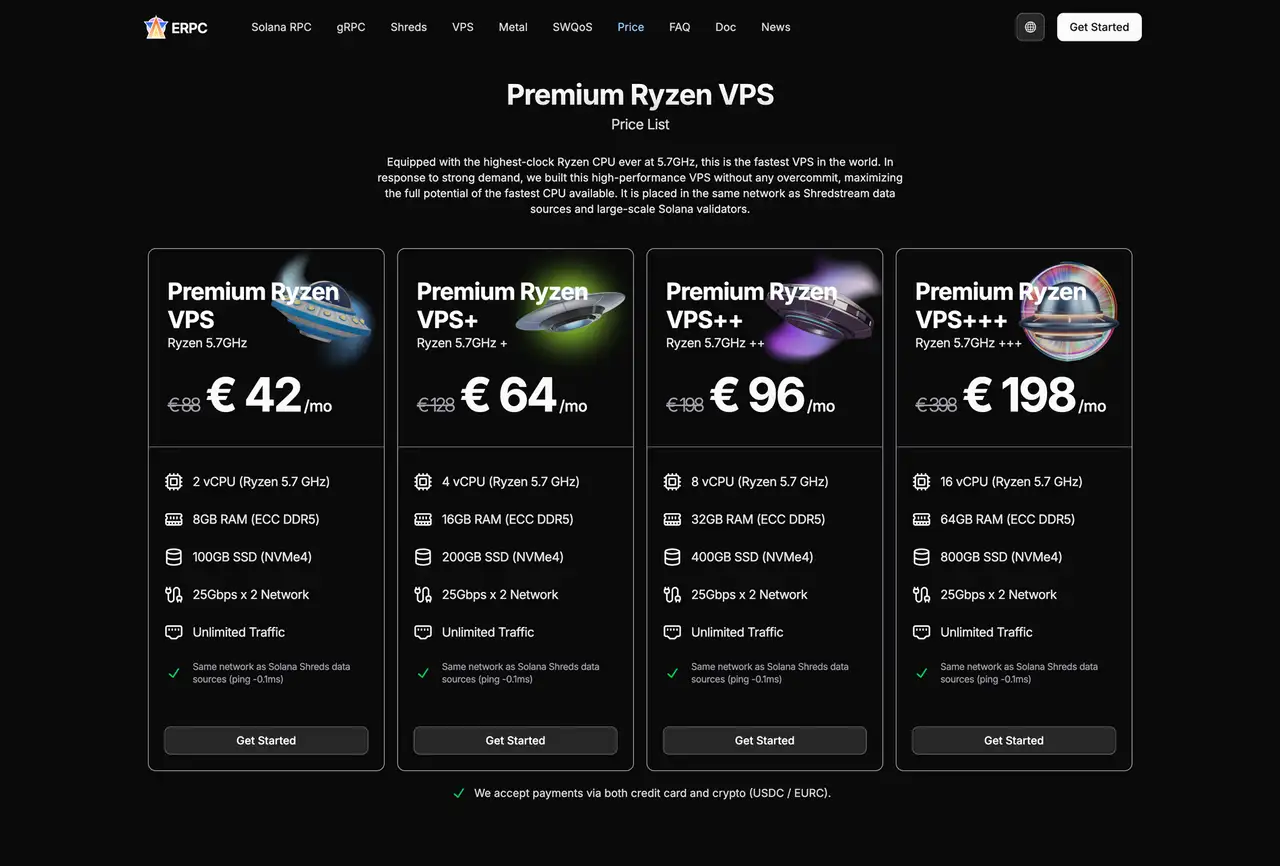
这些 VPS 实例运行在与以下组件相同的网络中:
- Jito Block Engine
- Shredstream 节点
- Geyser gRPC 节点
这种"零距离"配置允许你在不跨越外部网络的情况下,在领导者附近运行你的应用。
通过将 Bundle 方案与这些 VPS 产品结合,你可以同时优化:
- 网络距离
- 硬件性能
- 数据流质量
为延迟敏感的用例构建坚实基础。
从哪里开始(检查清单)
以下是你阅读完本文后可以立即采取的步骤:
-
测量到你当前 RPC / gRPC / Shredstream 端点的 ping 在短时间内多次测量,查看中位数而非单次样本。
-
在你的应用中添加日志以分离网络时间和处理时间 测量请求发送 → 响应接收,以及这两个时间点之间的内部处理。
-
检查哪些地区实际上靠近你的目标市场或 dApp 如果可能,从多个候选地区测量 ping,使你的决策基于数据而非直觉。
-
在靠近关键目标的地区部署单个 VPS 或 Bundle 并运行对比测试 记录并比较你的延迟相比现有环境改善了多少。
-
根据需要扩展到多地区架构 例如:法兰克福 + 纽约,法兰克福 + 东京,或法兰克福 + 新加坡,取决于你的策略。
-
长期来看,收集有关领导者时间表和验证者位置的数据 建立你自己对哪些地区在什么时间有优势的理解,并根据 epoch 变化持续调优你的网络布局。
总结:为什么应该从网络距离开始
如果你想在 Solana 上构建快速的交易或监控系统,你需要同时考虑代码、硬件和网络。其中,网络距离是:
- 最大的改进杠杆之一
- 最常被忽视的延迟来源之一
只要你从遥远的网络追赶领导者,总会有一些 slot 你在物理上无法赢得,无论你的代码和服务器优化得多好。
因此你应该:
- 正确测量你的网络距离
- 了解你实际在哪些网络中竞争
- 将应用迁移到对 Solana 有意义的位置
这些是通往真正性能的第一步。
ERPC 和 Validators DAO 提供专为 Solana 设计的网络和服务器资源,使这些架构在实践中切实可行且易于获取。
如果你想讨论网络距离优化或如何配置你的 Bundle 和 VPS 方案,欢迎通过 Validators DAO 官方 Discord 联系我们。
- ERPC 官方网站:https://erpc.global/en
- Validators DAO 官方 Discord:https://discord.gg/C7ZQSrCkYR


