

Waarom ERPC VPS hoge prestaties levert
Waarom ERPC VPS hoge prestaties levert

Wanneer ontwikkelaars beginnen met het bouwen van applicaties of bots op Solana, kiezen velen op basis van eerdere ervaring vanzelfsprekend voor grote, algemene clouds.
In de Web2-wereld waren deze clouds effectief de standaard en leverden ze voldoende prestaties.
Het is daarom natuurlijk om aan te nemen dat dezelfde aanpak ook geschikt zou zijn voor Solana.
Deze aanname faalt echter aanzienlijk voor Solana-werklast.
Grote, algemene clouds zijn ontworpen met veelzijdigheid en flexibiliteit als hoogste prioriteiten, en voor werklast zoals Solana waar lage latentie direct invloed heeft op uitkomsten, worden structurele verschillen onmiddellijk zichtbaar.
Dit artikel legt stap voor stap en zorgvuldig uit waarom Solana-werklast geen verwachte prestaties behaalt op grote algemene clouds, en hoe ERPC VPS is gestructureerd om deze problemen op te lossen.
Waarom "cloud-traagheid" bijna nooit wordt opgemerkt in Web2
Ten eerste zijn de meeste Web2-applicaties niet zo bedrijfskritisch als financiële applicaties.
Diensten zoals SNS, e-commerce, zakelijke tools en contentlevering kunnen een bepaalde hoeveelheid vertraging tolereren en toch als producten functioneren.
Om deze reden kwamen de volgende bronnen van structurele latentie binnen grote algemene clouds niet als problemen naar voren:
- Meerdere virtualisatielagen (virtuele NIC's, virtuele switches, enz.)
- Interne bandbreedte gedeeld door veel gebruikers
- CPU-overcommit (meer virtuele cores toewijzen dan fysieke cores)
- Extra processen voor facturering en monitoring
- Oudere CPU-generaties beschikbaar gesteld aan algemene gebruikers
Deze mechanismen zijn noodzakelijk voor cloudoperaties, maar bij Web2-werklast is hun impact gering en zijn er weinig gelegenheden om ze op te merken.
Solana-werklast is fundamenteel anders.
Web3-applicaties zitten "dicht bij financiën" en alles kan bedrijfskritisch worden
Applicaties gebouwd op Solana en andere blockchains bevinden zich dicht bij het financiële domein.
Activaverplaatsing, liquidatievoorwaarden, prijswijzigingen en transactievolgorde zijn allemaal direct verbonden met uitkomsten.
Met name marktgerelateerde werklast vereist transactievolume en snelheid die traditionele kaartbetalingen ver overtreffen.
Zelfs een paar milliseconden vertraging kan leiden tot mislukte uitvoering of slechtere prijzen.
Daarnaast is het gegevensvolume van Solana's chain extreem groot; correct abonneren op Shreds, logs en gRPC-events kan gemakkelijk resulteren in meerdere terabytes aan data per dag.
Dit verschilt fundamenteel van de typische Web2-verkeersprofielen waarvoor grote clouds oorspronkelijk zijn ontworpen.
Op deze manier biedt Solana geen mogelijkheid om de structurele latentie of kostenkenmerken die in deze clouds aanwezig zijn te verbergen.
Vanaf het begin verschijnen deze kenmerken direct als nadelen of operationele kosten.
Waarom grote algemene clouds niet geschikt zijn voor Solana
Hieronder leggen we factor voor factor uit waarom grote algemene clouds structureel niet passen bij de hogesnelheidsvereisten van Solana.
1. De CPU's die beschikbaar zijn voor algemene gebruikers zijn meerdere generaties oud
Bare metal-servers en VPS (VM's) die door grote clouds beschikbaar worden gesteld, gebruiken doorgaans CPU's die meerdere generaties achter liggen.
De nieuwste CPU's met hoge kloksnelheid passen niet bij de operationele efficiëntie of voorraadstrategie van de provider en verschijnen daarom zelden als door de gebruiker selecteerbare opties.
Voor Solana-werklast zijn single-thread prestaties en cachestructuur belangrijk, en verschillen in CPU-generatie beïnvloeden:
- Hoeveel transacties verwerkt kunnen worden
- Hoeveel streams verwerkt kunnen worden zonder achterstand op te lopen
- Hoe snel data verwerkt kan worden
2. Veel virtualisatielagen en lange netwerkpaden (hogere netwerklatentie)
Grote algemene clouds moeten veel verschillende applicaties tegelijkertijd draaien op gedeelde fysieke hardware.
Om dit te ondersteunen worden meerdere virtualisatie- en interne netwerklagen toegevoegd.
Voorbeelden zijn onder meer:
- Hypervisors voor het draaien van virtuele machines
- Virtuele NIC's en switches
- Interne firewalls en load balancers
- Facturerings- en monitoringagenten
Hoewel noodzakelijk voor cloudoperaties, vanuit het perspectief van Solana:
- Elk van deze verlengt het netwerk- en verwerkingspad
- Elk van deze introduceert latentie en jitter
Voor werklast die continu streamingdata verwerkt zoals Shreds of gRPC, accumuleren deze "extra tussenpunten" direct als nadelen.
3. Overcommit creëert instabiele prestaties
Grote clouds verhogen de efficiëntie door veel virtuele machines op één fysieke server te draaien.
Bijvoorbeeld, een server met een fysieke CPU van 64 cores kan veel VM's van 8 of 16 cores hosten, die opgeteld ver meer dan 64 virtuele cores bedragen.
Deze praktijk — meer virtuele cores toewijzen dan fysieke cores — is overcommit.
De aannames zijn:
- Niet alle VM's zullen tegelijkertijd 100% van hun CPU gebruiken
- CPU-tijd kan tussen VM's worden geleend afhankelijk van activiteit
Voor Web2-werklast zijn deze aannames redelijk geldig.
Echter, Solana-werklast omvat vaak meerdere processen die tegelijkertijd aanzienlijke CPU vereisen.
Op een overcommitted server treedt CPU-concurrentie vaker op en moet het besturingssysteem taken in een wachtrij plannen.
Het gevolg:
- Benchmarks kunnen snel lijken
- Werkelijke latentie in echte werklast varieert aanzienlijk afhankelijk van het tijdstip en de belasting van andere huurders
Voor Solana — waar transactietiming en streamverwerkingstiming direct de resultaten beïnvloeden — is deze jitter een groot nadeel.
4. Hoge dataoverdrachtvolumes resulteren in dure op verbruik gebaseerde facturering
Serieuze monitoring van Solana chain-data omvat vaak meerdere terabytes aan dagelijkse overdracht via Shreds, logs en gRPC-events.
Grote clouds brengen apart in rekening voor:
- Uitgaand netwerkverkeer
- Soms intern netwerkverkeer
- Opslag-I/O
Bij Web2-werklast zijn deze kosten verwaarloosbaar omdat het verkeersvolume klein is.
Maar voor Solana-werklast kan alleen al het abonneren op streams resulteren in netwerkkosten van honderden dollars per dag, waardoor voortgezette exploitatie onpraktisch wordt.
Grote algemene clouds zijn dus structureel en economisch niet afgestemd op Solana-werklast.
Waarom ERPC datacenters over de hele wereld heeft getest
Met begrip van deze beperkingen moesten we infrastructuur identificeren die daadwerkelijk geschikt was voor Solana.
Hiervoor hebben we datacenters over de hele wereld gehuurd en echte Solana-werklast gedraaid om hun gedrag te evalueren.
Zelfs binnen dezelfde stad varieert de geschiktheid voor Solana afhankelijk van:
- Gebouwstructuur
- Rackpositie
- Interne bekabeling
- IX'en en transitproviders
- Netwerkhard ware-prestaties en -configuratie
- ISP-capaciteit en routeringskwaliteit
- De hoeveelheid en kwaliteit van fysieke glasvezelroutes
- Bandbreedtegaranties tijdens congestie
Door herhaald testen hebben we duidelijk geïdentificeerd:
- Locaties die consistent en coöperatief gedrag vertonen voor Solana
- Locaties die dat niet doen, ongeacht geadverteerde specificaties
We hebben de laatste verwijderd en onze keuzes keer op keer verfijnd, waardoor uiteindelijk onze huidige infrastructuur en netwerkarchitectuur is gevormd.
Deze opgebouwde kennis ondersteunt direct de basis van ERPC VPS en RPC-infrastructuur.
Waarom ERPC VPS hoge prestaties levert
Het volgende legt uit hoe ERPC VPS structureel is ontworpen om hoogpresterende Solana-werklast te ondersteunen.
Verwijdering van onnodige lagen door focus op Solana-werklast
Grote algemene clouds bevatten veel lagen om een breed scala aan applicaties te ondersteunen.
De meeste van deze lagen bieden geen directe waarde voor Solana en creëren in plaats daarvan latentie.
Door te focussen op Solana-werklast verwijdert ERPC VPS:
- Lagen die onnodig zijn voor Solana-verkeer
- Componenten die alleen aanwezig zijn voor multifunctionele cloudoperaties
stuk voor stuk, op een zorgvuldige en gecontroleerde manier.
Dit is geen "vereenvoudiging omwille van de vereenvoudiging" maar een ontwerpprincipe:
behoud alleen wat betekenisvol is voor Solana en verwijder al het andere.
CPU's van de nieuwste generatie en ECC DDR5-geheugen
Grote clouds stellen over het algemeen geen CPU's van de nieuwste generatie beschikbaar aan gebruikers.
ERPC VPS maakt gebruik van deze CPU's en levert configuraties die equivalent zijn aan die welke worden gebruikt in Solana RPC- en Shredstream-nodes.
Dit voorkomt knelpunten door oude CPU-generaties en biedt een basis die in staat is om Solana's indexering, handelslogica en real-time analytics te verwerken.
Geen overcommit
Premium VPS overcommit nooit fysieke CPU-cores.
Elke toegewezen core wordt direct ondersteund door een fysieke core.
Dit voorkomt:
- Prestaties die variëren afhankelijk van andere huurders
- CPU-concurrentie onder zware belasting
Standard VPS houdt overcommit-ratio's ook extreem laag om stabiel CPU-gedrag te garanderen.
CPU's draaien altijd op maximale turbo
Veel serveromgevingen passen de CPU-frequentie dynamisch aan om redenen van stroomverbruik of thermiek.
Voor Solana-werklast kan dergelijke variabiliteit echter prestatiedalingen veroorzaken op kritische momenten.
ERPC VPS is afgestemd zodat CPU's op consistent hoge kloksnelheden werken, wat neerwaartse schommelingen onder belasting minimaliseert en prestatiestabiliteit waarborgt.
Draaien op de belangrijkste netwerkhubs van Solana
ERPC VPS is niet slechts "dicht bij onze eigen infrastructuur geplaatst."
Het draait rechtstreeks op de netwerken waar Solana-validators en stake wereldwijd geconcentreerd zijn.
Standard VPS is ingezet op een netwerk dat wereldwijd tweede staat in aantal validators en stake.
Premium VPS draait op het netwerk dat wereldwijd eerste staat in beide metrics, direct verbonden met een belangrijk knooppunt waar leaders en kernvalidators samenkomen.
Dus ERPC VPS:
- Deelt hetzelfde netwerk als ERPC's RPC-, gRPC- en Shredstream-infrastructuur, en
- Draait op precies die netwerken waar validators en stake het meest geconcentreerd zijn
Dit plaatst werklast fysiek en logisch dichter bij leaders.
Als gevolg hiervan zullen zelfs identieke code en logica structureel andere prestaties vertonen bij uitvoering op ERPC VPS vergeleken met grote algemene clouds — vooral bij leader-nabije detectie en transactieverzending.
RAID0 opslagconfiguratie
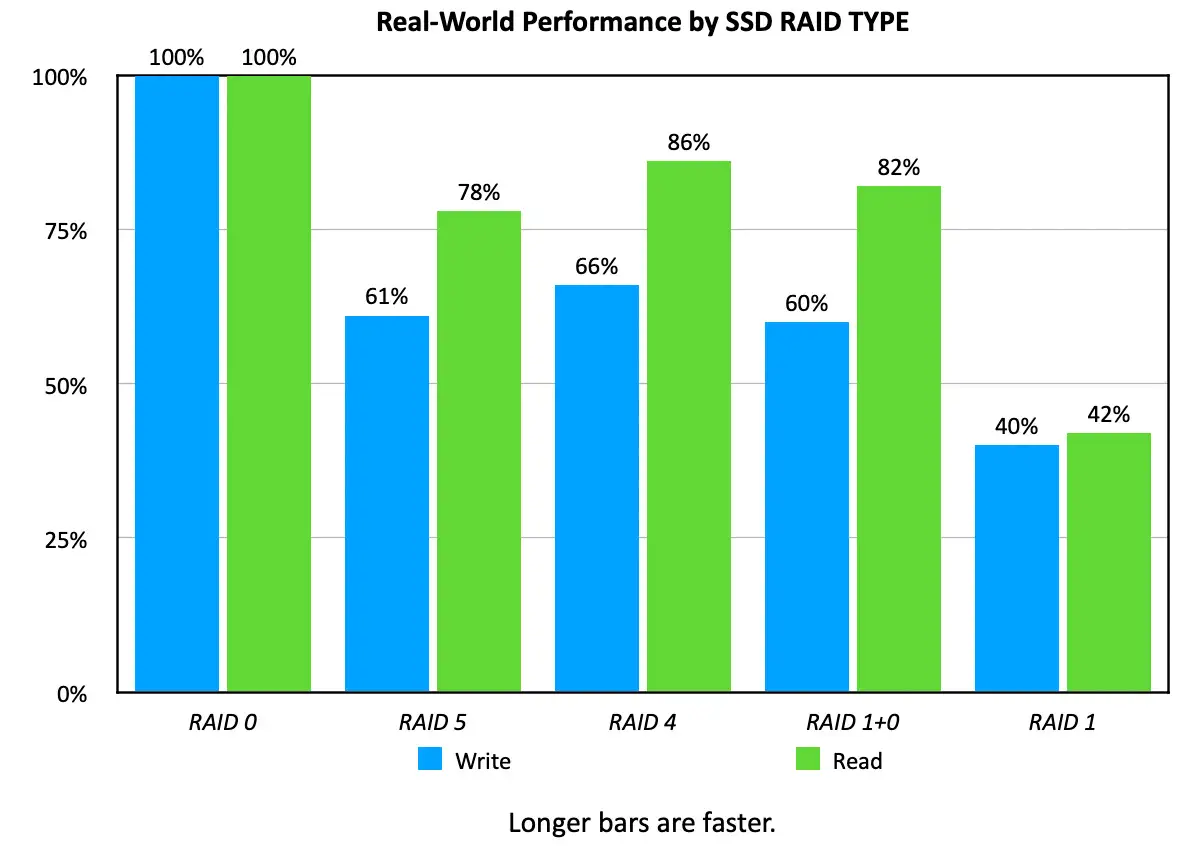
Veel cloud- en VPS-providers geven prioriteit aan gegevensbescherming en gebruiken daarom RAID10 of RAID4/5/6.
Voor Web2-systemen waar gebruikersgegevens op de server staan, is dit passend.
Echter, veel Web3-applicaties en Solana-nodes bewaren geen enkel onvervangbaar stuk data op de applicatielaag.
De blockchain zelf dient als een gedistribueerd grootboek, waardoor hersynchronisatie of herbouw mogelijk is.
Veel gebruikers geven ook de voorkeur aan prestaties boven mirroring, en de I/O-prestaties van opslag beïnvloeden direct het gedrag van Solana-nodes.
Om deze redenen gebruikt ERPC VPS RAID0 om de I/O-doorvoer te maximaliseren.
In Web3-infrastructuur is het kiezen van waar redundantie wordt geplaatst en op welke laag essentieel voor het balanceren van prestaties en veiligheid.
Referentie: Real-World Speed Tests for Different SSD RAID Levels
https://larryjordan.com/articles/real-world-speed-results-for-different-raid-levels/
Conclusie
Er is geen enkele factor die de prestaties van ERPC VPS verklaart.
CPU-generatie, overcommit-beleid, eliminatie van energiebesparende beperkingen en draaien op maximale turbo, datacentersselectie, netwerkpaden, RAID-configuratie en de mate waarin onnodige lagen worden verwijderd voor Solana-werklast — elk van deze factoren lijkt op zichzelf misschien klein, maar wanneer elk ervan grondig is verfijnd, wordt het cumulatieve effect de prestaties die ERPC VPS vandaag levert.
Door deze inspanningen hebben we een infrastructuur gebouwd die fundamenteel verschilt van grote, algemene clouds — een infrastructuur die gespecialiseerd is voor Web3- en blockchain-werklast.
Voor Solana vertaalt dit structurele verschil zich direct in betekenisvolle prestatievoorsprongen.
Voor configuratievragen, use case-discussies of implementatieplanning kunt u contact met ons opnemen via de Validators DAO Discord.
- ERPC Officiële Website: https://erpc.global/
- Validators DAO Officiële Discord: https://discord.gg/C7ZQSrCkYR
Nieuws


