

Benefits and Optimization of Multi-Region Solana Infrastructure
Benefits and Optimization of Multi-Region Solana Infrastructure

We have been emphasizing how important it is to stay physically close to the current leader validator. Still, Solana is globally distributed and leaders rotate constantly. Parking everything in a single city does not match that reality, which is why a multi-region approach makes sense. In this article, we start from epochs and the leader schedule, then show how to decide whether you are “close” in practical terms and how to operationalize that decision.
Grasp epochs and the leader schedule
Solana advances time in slots. Roughly 400 ms make one slot, and slots are grouped into an epoch. An epoch is a set of slots (432,000 in total) and feels like about two days. You can track progress with the RPC method getEpochInfo. To understand the network’s current processing pace and how fast slots are advancing, getRecentPerformanceSamples is useful. At the start of each epoch the leader schedule is fixed, and at any moment exactly one leader is producing the block. This rapid turnover is the reason you need an approach that follows distance as leaders change.
Why distance affects outcomes
In the history of trading infrastructure, being physically close to the exchange’s main servers has always been an advantage. People even say the price of server changes with cable length. Light is fast, but not infinite. Shorter distance means faster receive and faster send. The same principle applies on a blockchain, with one difference: Solana’s point of block production moves around the world. If the leader stands in New York right now, being near New York helps. If the next leader is in Frankfurt, being near Frankfurt helps. This is why you prepare multiple locations instead of one single hub.
The core multi-region strategy
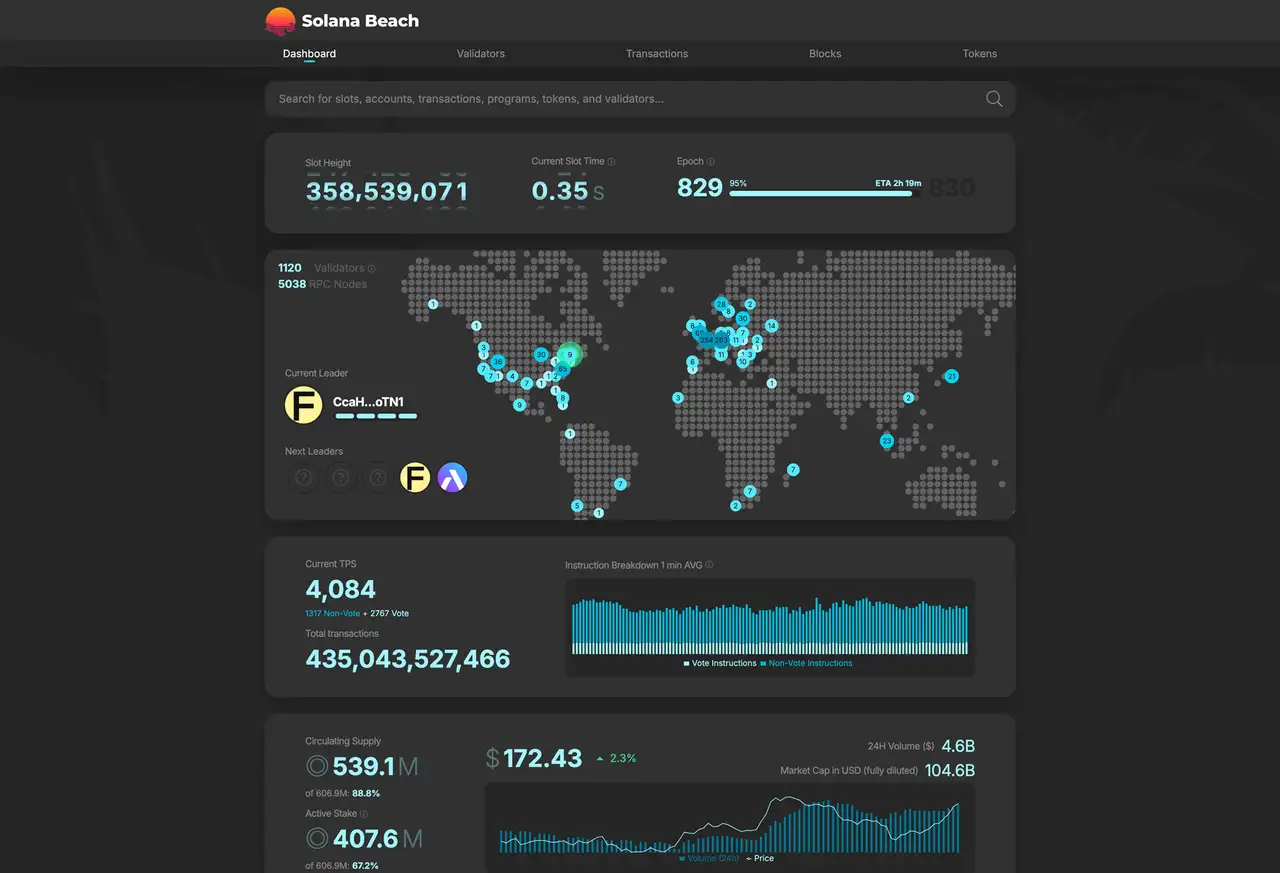
Keep several small footholds in major validator cities and exchange points, and automatically use the foothold that is closest to the current leader at any given moment. When the leader slot is in New York, receive and send from New York. When the next leader rotates to Frankfurt, hand off to Frankfurt immediately and transmit from there on the shortest path. The goal is not to improve an average, it is to avoid missing the opportunities that keep arriving.
Choose dedicated, not shared
Shared networks and shared servers are sensitive to other users and tend to wobble at peak times. Dedicated endpoints and dedicated servers across regions let you bypass congestion and pass data like a private expressway. Stream reception is especially sensitive to distance, so placing it closest on dedicated resources affects what you feel day to day. Transmission also behaves as intended only when it leaves from a nearby foothold over a dedicated route (you are the only user, so you are less affected by shared throttling and queueing).
How to measure “closeness”
Closeness is a data decision, not a gut feeling. First, find where you are in the current epoch. Use getEpochInfo to fetch epoch data and read elapsed slots and remaining slots. Then use getRecentPerformanceSamples to estimate the recent average slot time. Remaining slots multiplied by the average slot time gives you a rough number of seconds until the switch. That makes it easier to plan preparation and location hand-offs.
As the switch approaches, fetch the leaders for your target range with getSlotLeaders and narrow down near-term candidates. You can list cluster nodes with getClusterNodes. Cross-reference the leader’s identity with node data, then use the public IP or gossip address to estimate geographic candidates.
Be careful here. IP geolocation can be wrong or stale, so once you have a rough map, actually ping from each of your footholds and measure the round-trip baseline directly. The network behaves like a road trip: distance matters, but route choice changes arrival time. Ping is a compact indicator of how crowded today’s “roads” are. Do not rely on a single measurement. Run several lightweight pings in a short window and decide based on the median to reduce noise.
Do not throw away the results. Store measurements and mappings per foothold in your own database, and have a lightweight worker update deltas at each epoch change. Day-to-day operations become steadier and your decisions become faster.
Turn it into a system with a database and workers
If you recompute everything from scratch, your speed is spent on measurement itself. In practice, store the mapping between leaders and regions, plus per-foothold latency, in your database. Update it with a worker at each epoch boundary. Let the runtime application read that database and decide instantly which foothold to use. Place reception near the stream source, and prepare transmission in the next leader’s region a little early. Splitting roles lowers the total combined latency.
Micro-level tuning and macro-level design
Per foothold, use high-clock CPUs, DDR5 memory, and the latest NVMe, and keep typical utilization low. Micro-level tuning is the base that makes multi-region design pay off. At the macro level, co-locate dedicated endpoints and servers inside the same network to maximize “zero-distance communication” that does not cross the public internet. For inter-foothold relays, your own dedicated paths often reduce hand-off wait time compared to generic routes via public RPC.
Implementation and support
Receive near the leader, send from near the leader. Since “near” keeps changing, spread your footprint across multiple regions. What you need is a small mechanism to track the latest schedule and a sensible way to place footholds. We do not provide trading or financial advice. We can, however, help as builders with concrete steps to shorten data round trips. This includes designing your database and workers, placing footholds, preparing dedicated endpoints, and handing off between cities.
For updates and questions, join the Validators DAO Discord. Free trials and test environments are available.
https://discord.gg/C7ZQSrCkYR
Thank you as always. We continue to test in the field and improve honestly, so that your project succeeds.
News


